Machine Learning in iOS
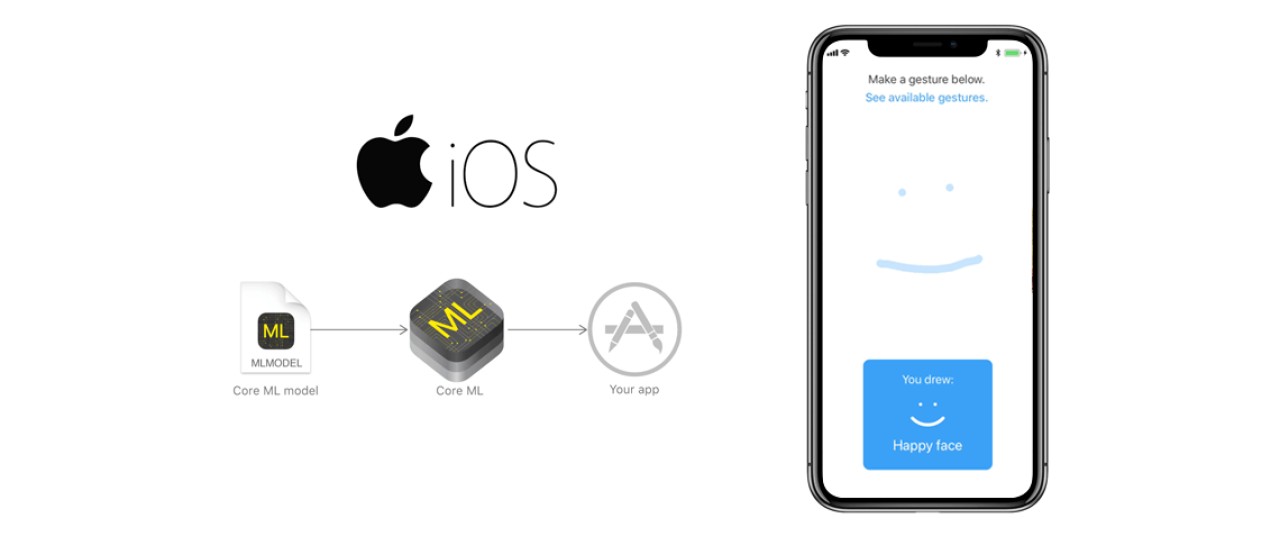
Fifty years ago, machine learning was still the stuff of science fiction. Today it’s an essential part of our lives, helping us do everything from finding photos to driving cars.
Machine learning is a type of artificial intelligence where computers “learn” without being explicitly programmed. Instead of coding an algorithm, machine learning tools enable computers to develop and refine algorithms, by finding patterns in huge amounts of data.
In this article, you’ll learn about Core ML and Vision, two cutting-edge iOS frameworks. You’ll also get a quick overview of machine learning fundamentals.
Deep Learning
Since the 1950s, early AI thinkers and tinkerers have developed many approaches to machine learning. But, neural networks have been experiencing a massive boom later. In 2012, a neural network created by Google learned to recognize humans and cats in YouTube videos — without ever being told how to characterize either. It taught itself to detect felines with 74.8% accuracy and faces with 81.7%.
At the moment deep learning is making big waves. It is a branch of machine learning that uses algorithms to e.g. recognize objects and understand human speech. Scientists have used deep learning algorithms with multiple processing layers to make better models from large quantities of training data.
To use the model, you give it new inputs, and it calculates outputs: this is called inferencing. Inference still requires a lot of computing, to calculate outputs from new inputs.
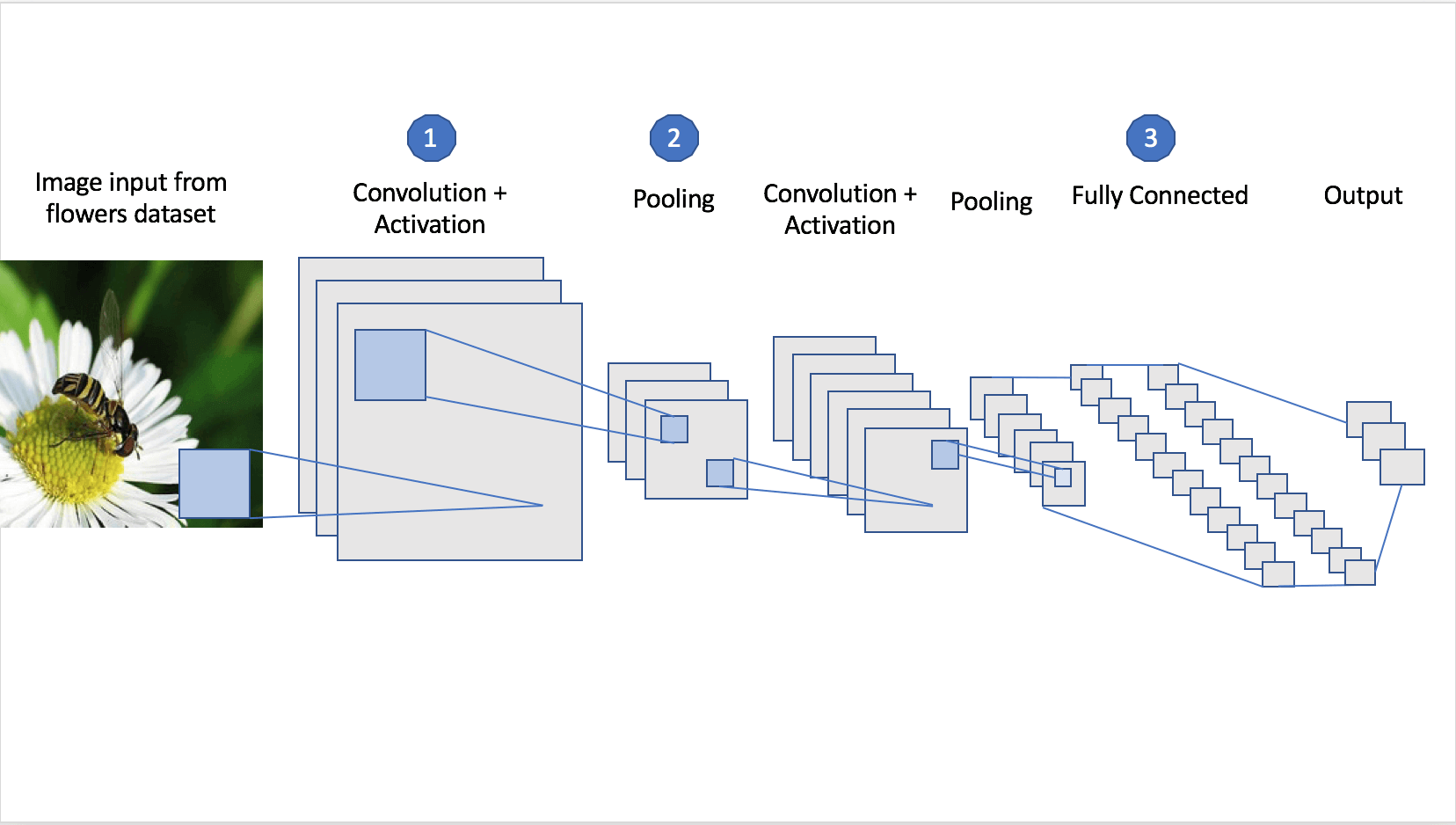
In a nutshell, if we give the computer a picture of a cat and a picture of a ball, and show it which one is the cat, we can then ask it to decide if subsequent pictures are cats. The computer compares the image to its training set and makes an answer. Today’s algorithms can also do this unsupervised; that is, they don’t need every decision to be pre-programmed.
A brief history of Apple ML
CoreML has only been public since the release of iOS 11 in September 2017, and already supported by every major ML platform to convert existing models. But the existing models tend to be too big and/or too general.
Create ML was announced at WWDC 2018. It currently includes only two task-focused toolkits, plus a generic classifier and regressor, and data tables.
Create ML
Create ML speeds up the workflow for improving your model by improving your data while also flattening the learning curve by doing it all in the comfort of Xcode and Swift.
You can use Create ML with familiar tools like Swift and macOS playgrounds to create and train custom machine learning models on Mac OS. Also, you can train models to perform tasks like recognizing images, extracting meaning from text, or finding relationships between numerical values.

Diagram showing a Create ML workflow: Gather data, train the model, and evaluate the trained model

Create ML leverages the machine learning infrastructure built into Apple products like Photos and Siri. This means image classification and natural language models are smaller and take much less time to train.
The Image Classifier Model
To train a Create ML image classifier, provide it with a training dataset — a folder containing the class folders.
After training the model, you will need a testing dataset to evaluate the model. To evaluate how well the model works on images it hasn’t seen before, the images in the testing dataset should be different from the images in the training dataset. If collecting data would put 20% of the images in the testing dataset, and the rest in the training dataset.
Apple’s Party Trick
In Xcode 10, create a new macOS playground, and enter this code:
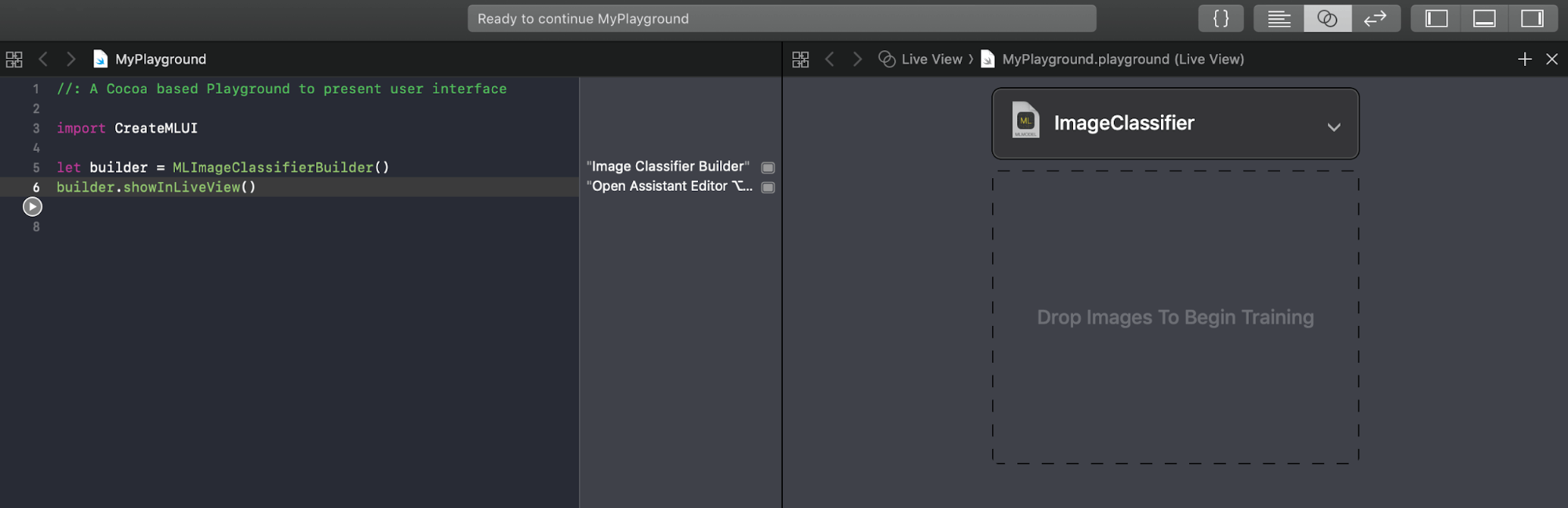
You’re creating and showing an interactive view for training and evaluating an image classifier. The algorithms are already good and can let the data science researchers carry on with making them better. Most of the time, effort, expense of machine learning goes into curating the datasets. And this GUI image classifier helps hone data curating skills.
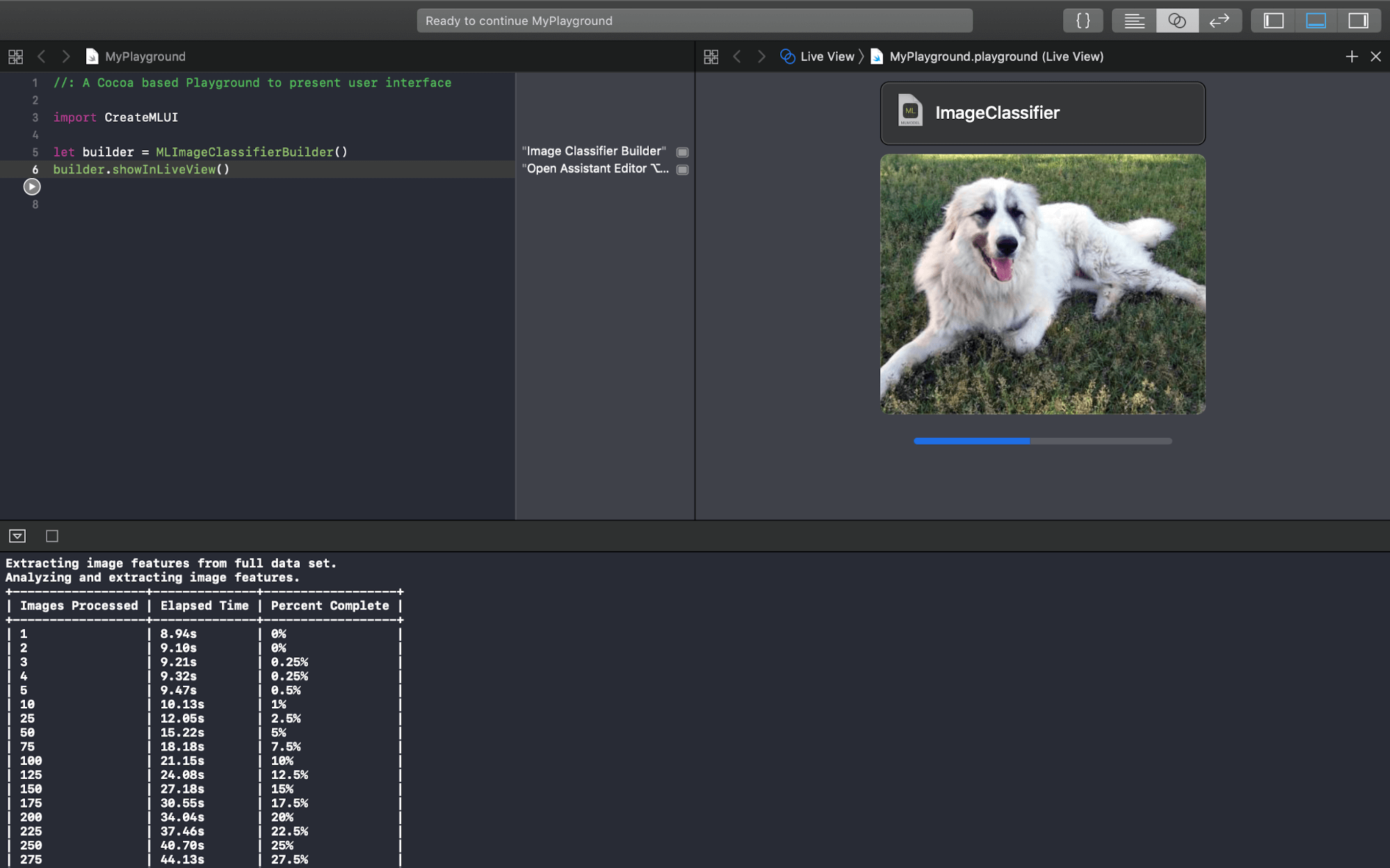
When training finishes, the view displays Training and (sometimes) Validation accuracy metrics, with details in the debug area:
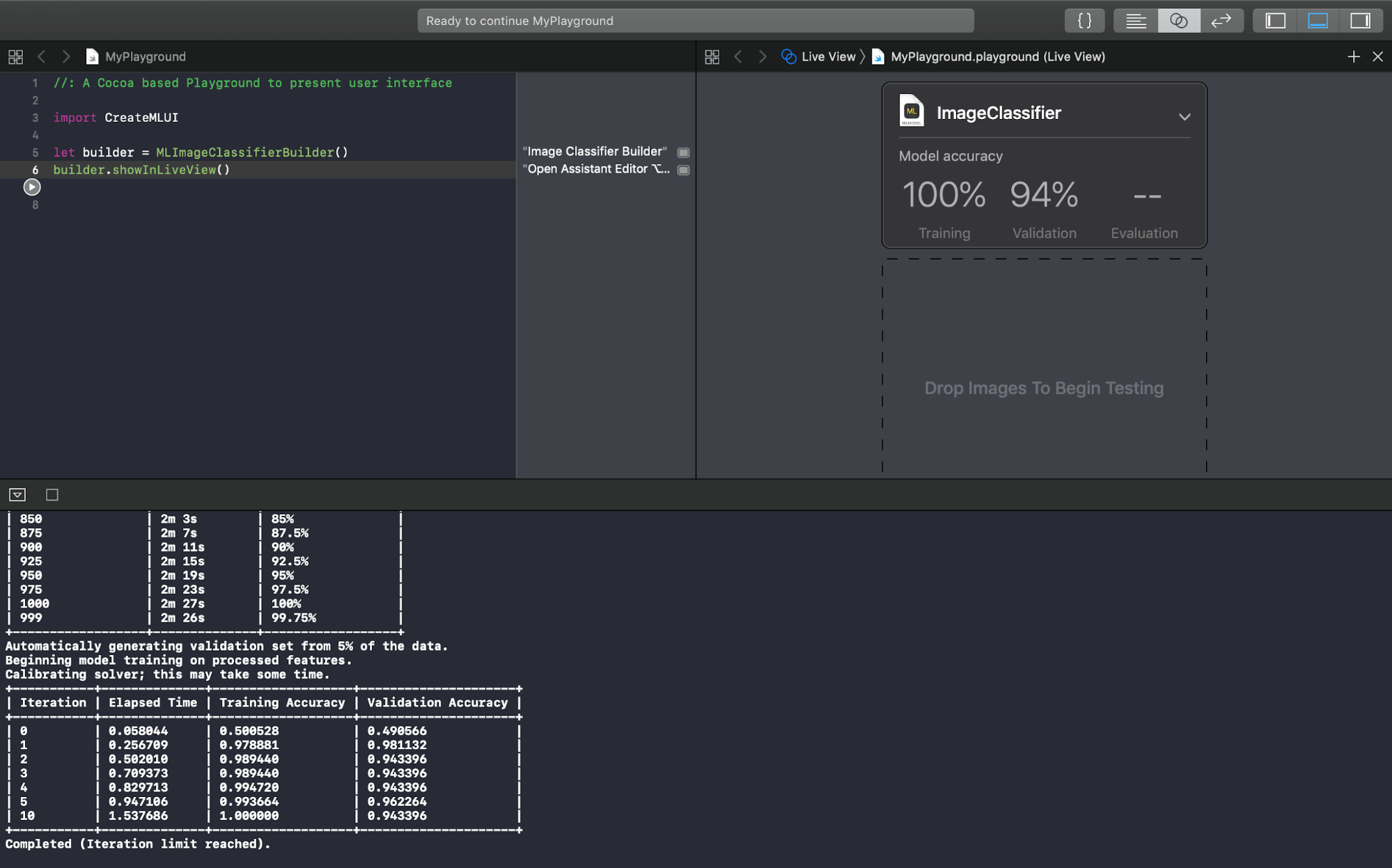
So what’s validation? And what do the accuracy figures mean?
Training involves figuring how much weight to give each feature to compute the answer. Then, to refine the weights, it feeds the right-or-wrong information into the next iteration.
Validation accuracy is similar. Before training starts, a randomly chosen 10% of the dataset is split off to be validation data. Features are extracted and answers are computed with the same weights as the training dataset. But the results aren’t used directly for recomputing the weights. Their purpose is to prevent the model overfitting — getting fixated on a feature that doesn’t actually matter, like a background color or lighting. If validation accuracy is very different from training accuracy, the algorithm makes adjustments to itself. The choice of validation images affects both the validation accuracy and training accuracy.
Improving Training Accuracy
- Increase Max iterations for image classifiers.
- Use different algorithms for text classifiers.
- Use different models for generic classifiers or regressors.
Improving Validation Accuracy
Increase the amount of data: for image classifiers, you can augment your image data by flipping, rotating, shearing or changing the exposure of images.
Improving Evaluation Accuracy
Make sure the diversity of characteristics of your training data match those of your testing data, and both sets are similar to the data your app users will feed to your model.
The Text Classifier Model
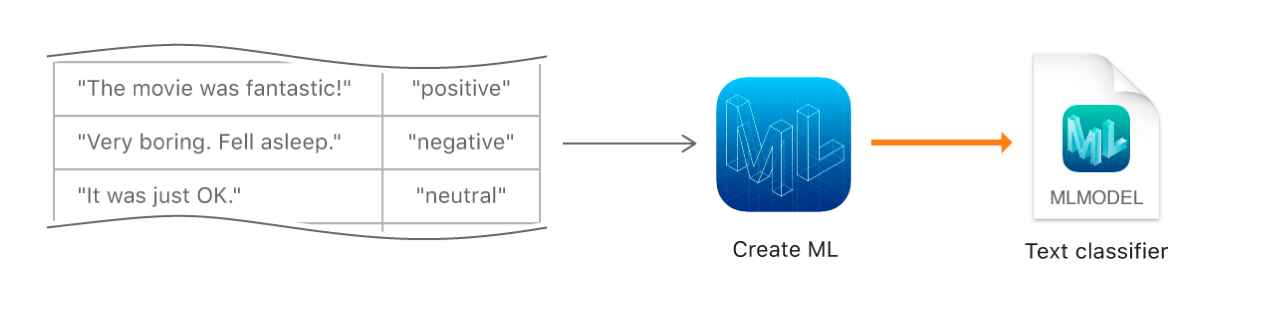
A text classifier is a machine learning model that’s been trained to recognize patterns in natural language text.
Train a text classifier by showing it lots of examples of text have already labeled.
Diagram showing how you train a text classifier with Create ML using training data.
Import Data
Start by gathering textual data and importing it into an MLDataTable instance. You can create a data table from JSON and CSV formats. Or, if textual data is in a collection of files, you can sort them into folders, using the folder names as labels.
The resulting data table has some columns, derived from the keys in the JSON file. The column names can be anything, as long as they are meaningful because they will use them as parameters in other methods.
Prepare Data for Training and Evaluation
The data used to train the model needs to be different from the data used to evaluate the model.
Create and Train the Text Classifier
Create an instance of MLTextClassifier with a training data table and the names of your columns. Training begins right away.
To see how accurately the model performed on the training and validation data, use the classificationError properties of the model’s trainingMetrics and validationMetrics properties.
Evaluate the Classifier’s Accuracy
Next, evaluate the trained model’s performance by testing it against sentences it’s never seen before. Pass your testing data table to the evaluation(on:) method, which returns an MLClassifierMetrics instance.
To get the evaluation accuracy, use the classificationError property of the returned MLClassifierMetrics instance.
If the evaluation performance isn’t good enough, may need to retrain with more data or make other adjustments.
Save the Core ML Model
If the model is performing well enough, you can save and use it in the app. Utilize the write method to write the Core ML model file to disk. Provide any information about the model, like its author, version, or description in an MLModelMetadata instance.
Integrating a Core ML Model into App
First, you have to add a Model to your Xcode project by dragging the model into the project navigator. Now, you can see information about the model—including the model type and its expected inputs and outputs—by opening the model in Xcode.
Create the Model in Code
Xcode also uses information about the model’s inputs and outputs to automatically generate a custom programmatic interface to the model, which used to interact with the model in code.
Build and Run a Core ML App
Xcode compiles the Core ML model into a resource that’s been optimized to run on a device. This optimized representation of the model is included in the app bundle and is what’s used to make predictions while the app is running on a device.
I hope you found this article useful. Feel free to join the discussion below!

 (4 votes, average: 4.00 out of 5)
(4 votes, average: 4.00 out of 5)Stay tuned. Monthly digest of the best stories.



