Comparison of Relational and Graph Databases on the Example of Neo4j and PostgreSQL in the Context of Spring Data

Conceptual Differences of Models
First, let’s have a look at these two approaches and determine why and when we need to use graph databases instead of relational ones in enterprise Java products.
A relational model is a collection of data which consists of a two-dimensional table set. In set theory, the table corresponds to the term relation. The table is the representation of the relation. Therefore, this model was named “relational”. The theory of building databases is a supplement to the data processing tasks of such branches of mathematics as set theory and first-order logic. Compared to the hierarchical and network data model, the relational model has a higher level of data abstraction. The relational model is a convenient and most familiar form of data presentation, so at present, this model is a de facto standard that almost all modern commercial DBMSs are oriented on.
The principles of the relational model were first formulated in 1969-1970 by E. F. Codd (E. F. Codd). Codd’s ideas were first publicly presented in the article “A Relational Model for Large Shared Data Banks”. A modern interpretation of the ideas of the relational data model can be found in the book of C. J. Data. “C. J. Date. An Introduction to Database Systems ».
When tabular data organization there is no hierarchy of elements. Rows and columns can be viewed in any order, so there is high flexibility in selecting any subset of elements in rows and columns. Any table in a relational database consists of rows, which are called records, and columns, which are called fields. At the intersection of the rows and columns are specific data values. For each field is determined by the set of its values.
Graph databases store relationships in the individual record level which is lower than the structure that is created in relational databases – relationships are represented by tables.
And here we have the main difference – relational databases work faster because they don’t need to iterate through the relationships – they are already defined. The other thing – is that is graph databases need more space to store the relationships.
So storing all the relationships at individual record layer is a nice approach when we need to expand our object model in runtime – we can easily add some new relationships like other entities. But in the real world, most databases require regular, relatively simple structures. In Java, for example, we have predefined object model which can be changed along with the database migrations but it cannot be performed in runtime.
Comparison of Spring Data Classes Mapping With JPA and OGM
OGM is an object mapping library for Neo4j which is used in Spring Data and JPA is a specification that describes the management of relational data in applications.
Let’s review and compare working with these approaches in the context of Spring Boot application.
Here are the same classes with different mapping- first is for Neo4j and the second is for JPA: we can notice that both mappings are not heaping, but there is a very important difference – in JPA you have to define all the references, while in Neo4j mapping you can just define your class as @NodeEntity and all the references will be transferred to Neo4j database.
@Data public class Club { @Id @GeneratedValue private Long id; private String name; @Relationship(type = "player") private List<Player> players; @Relationship(type = "birthplace") private Country country; @Relationship(type = "director") private Person director; }
Reference example from Player entity with OGM:
@Data @NodeEntity @EqualsAndHashCode(exclude = "club", callSuper = true) public class Player extends Person { @Relationship(type = "player", direction = Relationship.INCOMING) private Club club; private Integer number; @Relationship(type = "position") private Position position; }
Here is Neo4j annotation class mapping with Spring Data. This mapping is quite simple – all we have to do is define our class as @NodeEntity, define what field will be an id of an entity, define all the relationships between classes. In this example we have the relationship “player” from Club to Player entities, so we need to define the outgoing relationship in the Club class and incoming relationship in the Player class.
And here is JPA annotation mapping most Java enterprise developers are used to. We need to define our @Entity class, choose what field will be an id of this entity and define all the relations.
Reference to Club entity in JPA is defined as @OneToMany:
@Data @Entity @Table(name = "person") @Inheritance(strategy = InheritanceType.JOINED) public class Person{ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(columnDefinition = "serial") private Long id; @Column(name = "name") private String name; @Column(name = "surname") private String surname; @Column(name = "age") private Integer age; @ManyToOne(fetch = FetchType.EAGER,cascade = CascadeType.ALL) @JoinColumn(name = "country_id") private Country birthplace; }
The mapping of the Club entity:
@Entity @Data @Table(name = "club") public class Club { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(columnDefinition = "serial") private Long id; private String name; @OneToMany(mappedBy = "club") private List<Player> players; @ManyToOne(fetch = FetchType.EAGER, cascade = CascadeType.ALL) @JoinColumn(name = "country_id") private Country country; @ManyToOne(fetch = FetchType.EAGER, cascade = CascadeType.ALL) @JoinColumn(name = "director_id") private Person director; }
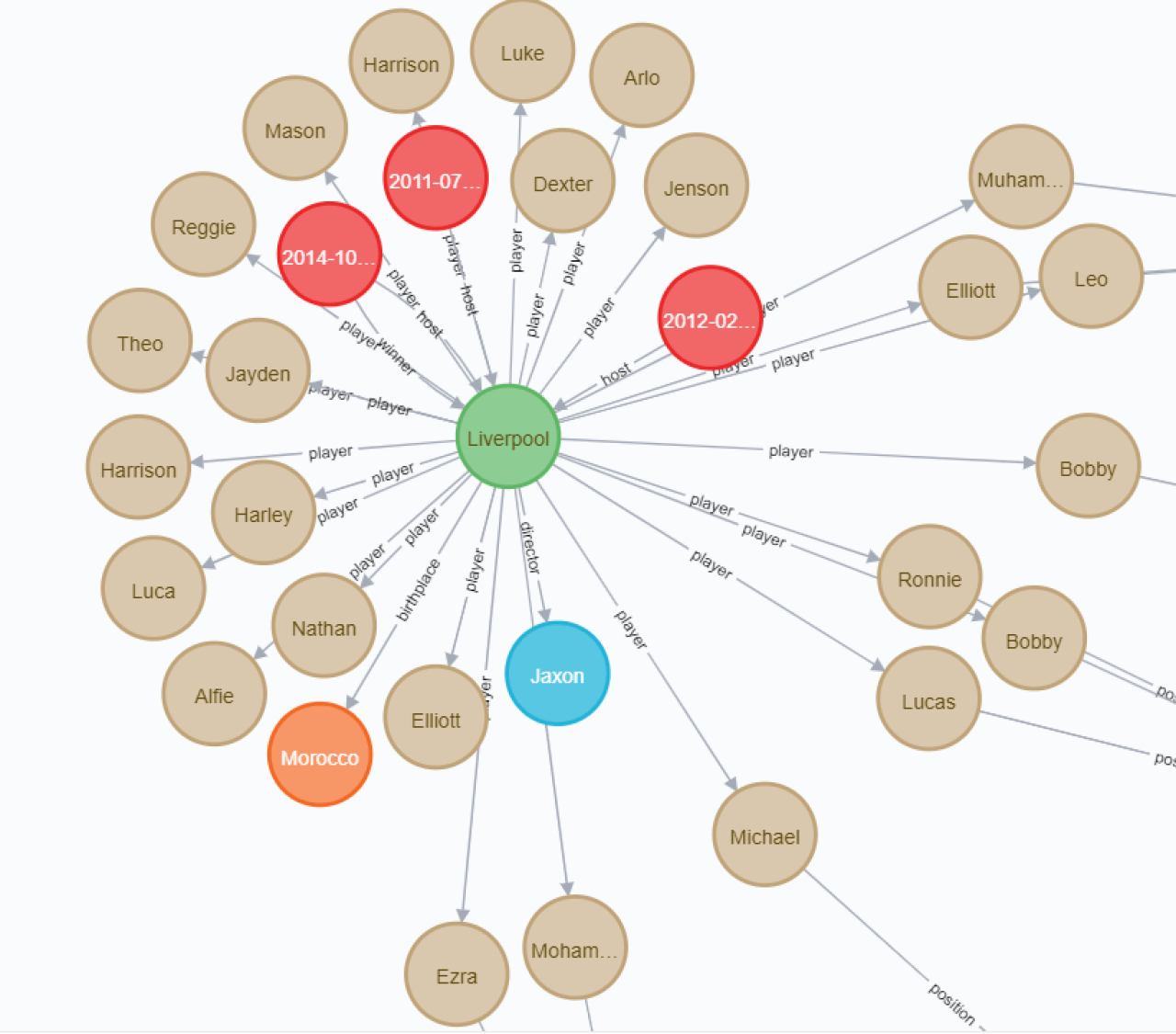
One interesting feature – if we don’t define references in our class in Neo4j mapping it will create all of them, but if we have reference to Players in Club class and reference to Club in player class, Spring Data will create 2 different relationships, that will look like (upper case field names):
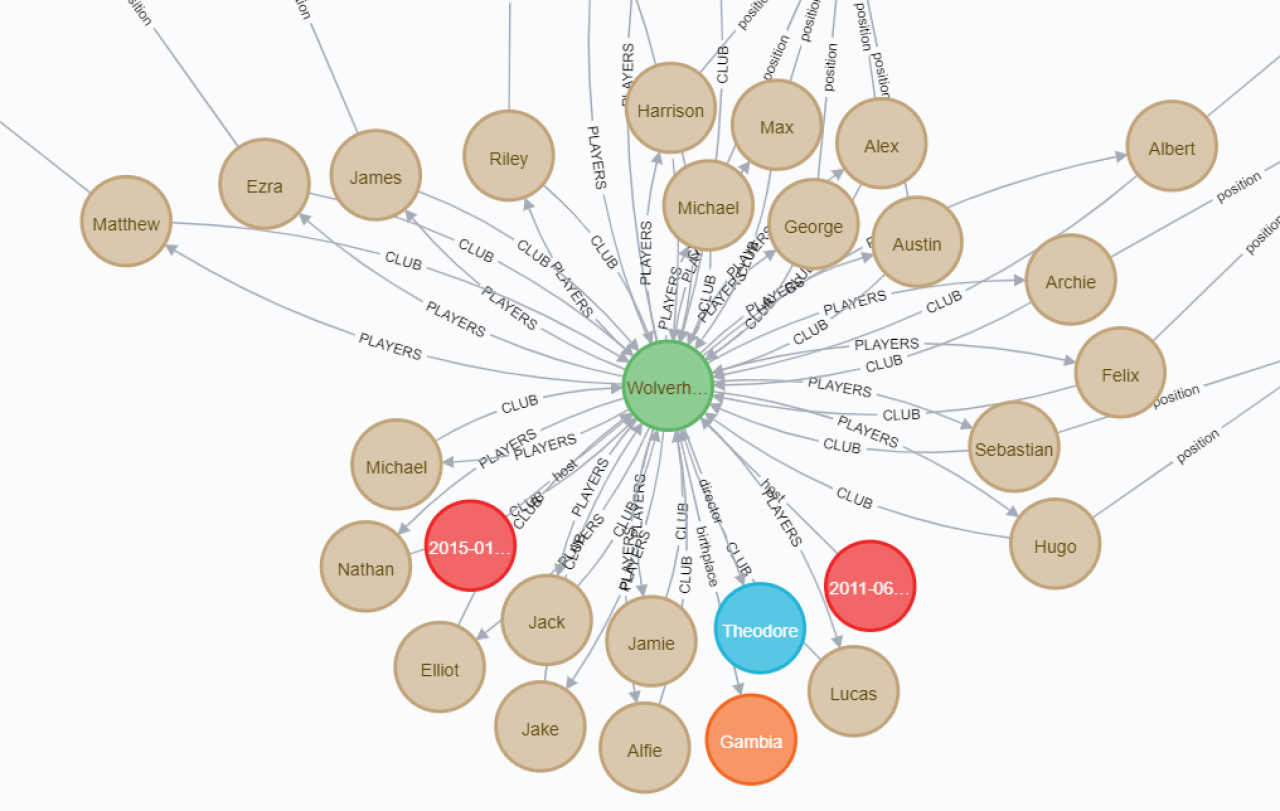
Using the mapping which was presented before, DB entities look like:
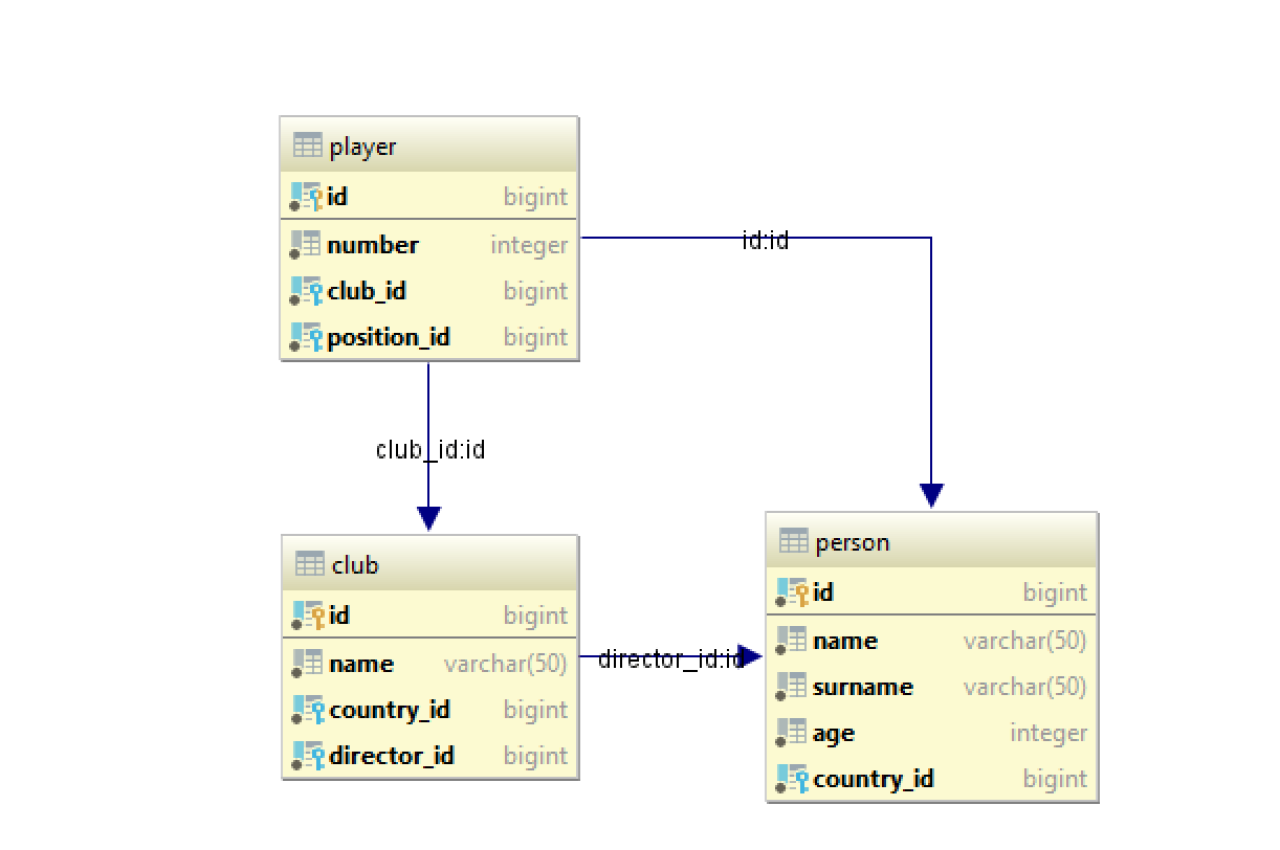
In the relational database, this reference will be mapped like it is shown in the picture below:
Performance Analysis
In order to test performance, we have developed a test application with football as the subject domain.
Description:
- Match has a winner and two sides – host and guest which are represented by Club entities. It also has a Stadium – where was the match;
- Club has a list (size of the list is always 25) of Players and a director, which is represented by Person entity;
- Actually Player is a Person, and he has the Country where he was born, Position on a field and a Club for which he plays;
- There are some simple properties for all of the entities, like players age, etc.
We used PostgreSQL as a relational database and Neo4j as a graph database.
Lazy initialization in Hibernate was changed to eager in order to make the comparison fair.
The test was pretty easy – we have created some number of matches between the equal number of teams (all the entities were generated randomly) and saved them. Then we spotted the average time of getting all the entities from the database. We didn’t need to change the Repository classes – there are implementations of CrudRepository both for JPA for relational databases and for Neo4j in Spring Data.
Here are the test results:
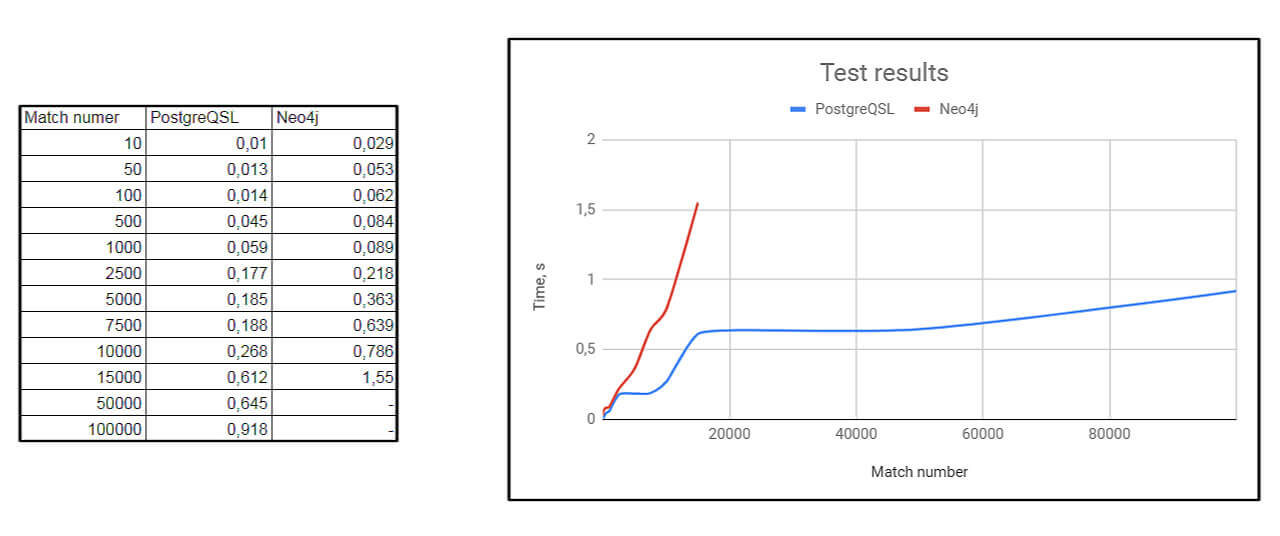
Test of Neo4j with OGM of more than 15000 matches (420283 entities in total) throws OutOfMemoryError, so there is no data for these values in the graph.
According to this graph, we can say that Neo4j works much slower on the big amount of data which is a great disadvantage.
Conclusion
The comparison table of graph databases and relational databases in the context of Spring Data is given below:
| Graph database | Relational Database | |
| Object-Relational Mapping | + | + |
| Fast handling big amount of data | – | + |
| Transactions | + | + |
| Flexibility | + | +- |
| Storage | – | + |
| Spring Data support | + | + |
| ORM eager initialization | – | + |
| ORM caching | – | + |
As we can see there are a lot of features that are not implemented in OGM, along with its performance issues it raises the question of the advisability of using Neo4j in your Java applications.
 (2 votes, average: 5.00 out of 5)
(2 votes, average: 5.00 out of 5)Stay tuned. Monthly digest of the best stories.




Comments are closed.