Web Scrapping with C#

Often we need to obtain data from various web pages, filter, analyze and save it in a structured form. There are many reasons for collecting and analyzing large amounts of information:
- Monitoring of product prices online;
- Collection and analysis of exchange rate;
- Getting contact information from different sites to create your own lists of suppliers, manufacturers or any other persons of interest;
- Filling content with your own site, using information from partner sites.
The last point was the starting point for the study and implementation of this engine.
Web Scraping is a popular and convenient implementation method which algorithm enters on the site’s start page and follows all internal links and extracting information from the specified tags.
This article will present and describe the implementation of Web Scraping in the C# programming language.
For implementation, we use the ScrapySharp library, which has a built-in web client and allows a web browser emulating. To parsing HTML, we utilize CSS selectors, XPath and LINQ. This structure is a wrapper for the equally well-known HtmlAgilityPack library. An important point is that this library has an open source code and MIT license.
To install the ScrapySharp library into a project, you should run the command in the Package Manager PM > Install-Package ScrapySharp or connect the Nuget-package using the graphical interface. Now you can use this library.
As an example, we will use the Swedish website www.undertian.com for a better understanding of information. The subject of information collection will be the recipe of dishes. To start we will define the object fields that will be our template for the collected information.
public class Recipe
{
public string Title { get; set; }
public string Ingredients { get; set; }
public string Description { get; set; }
public string CookingSteps{ get; set; }
public string ImageUrl { get; set; }
public string ExternalLink { get; set; }
public string ServingsCount { get; set; }
public string CookTime { get; set; }
public string MealPrice { get; set; }
public string Diet {get; set; }
}
The next step is to create a web browser and load a web page:
ScrapingBrowser browser = new ScrapingBrowser();
WebPage page = browser.NavigateToPage(new Uri("https://undertian.com/recept/"));
The NavigateToPage method returns a WebPage-object. The page is represented as HtmlNode objects. Using the InnerHtml property, you can view the HTML code of the element. InnerText allows you to get the text inside the element. To extract the necessary information and determine which tag contains it, we recommend using a browser developer tool or free web proxy Fiddler debugger.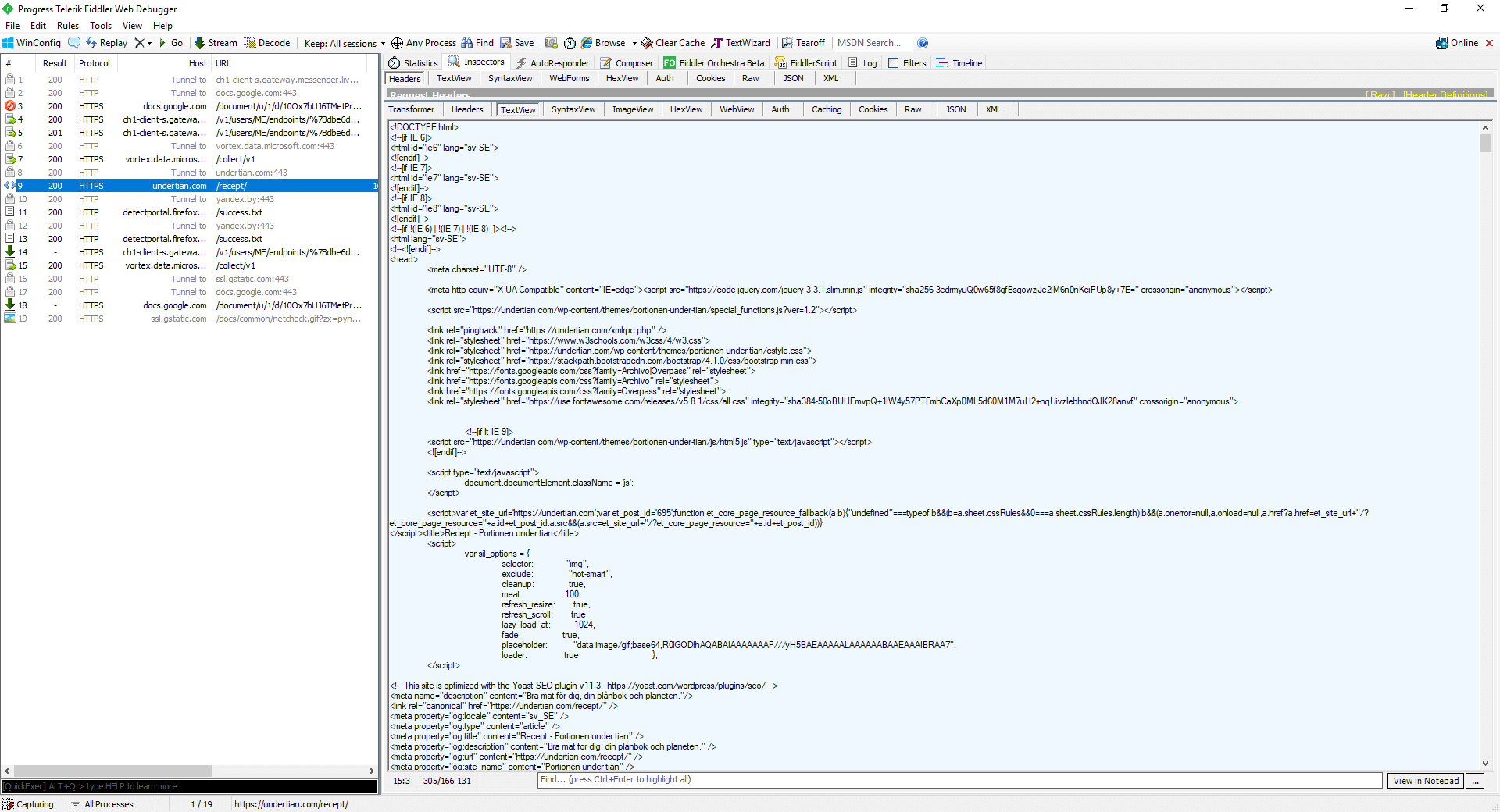
It is more convenient for me to use the developer tool in Firefox browser.
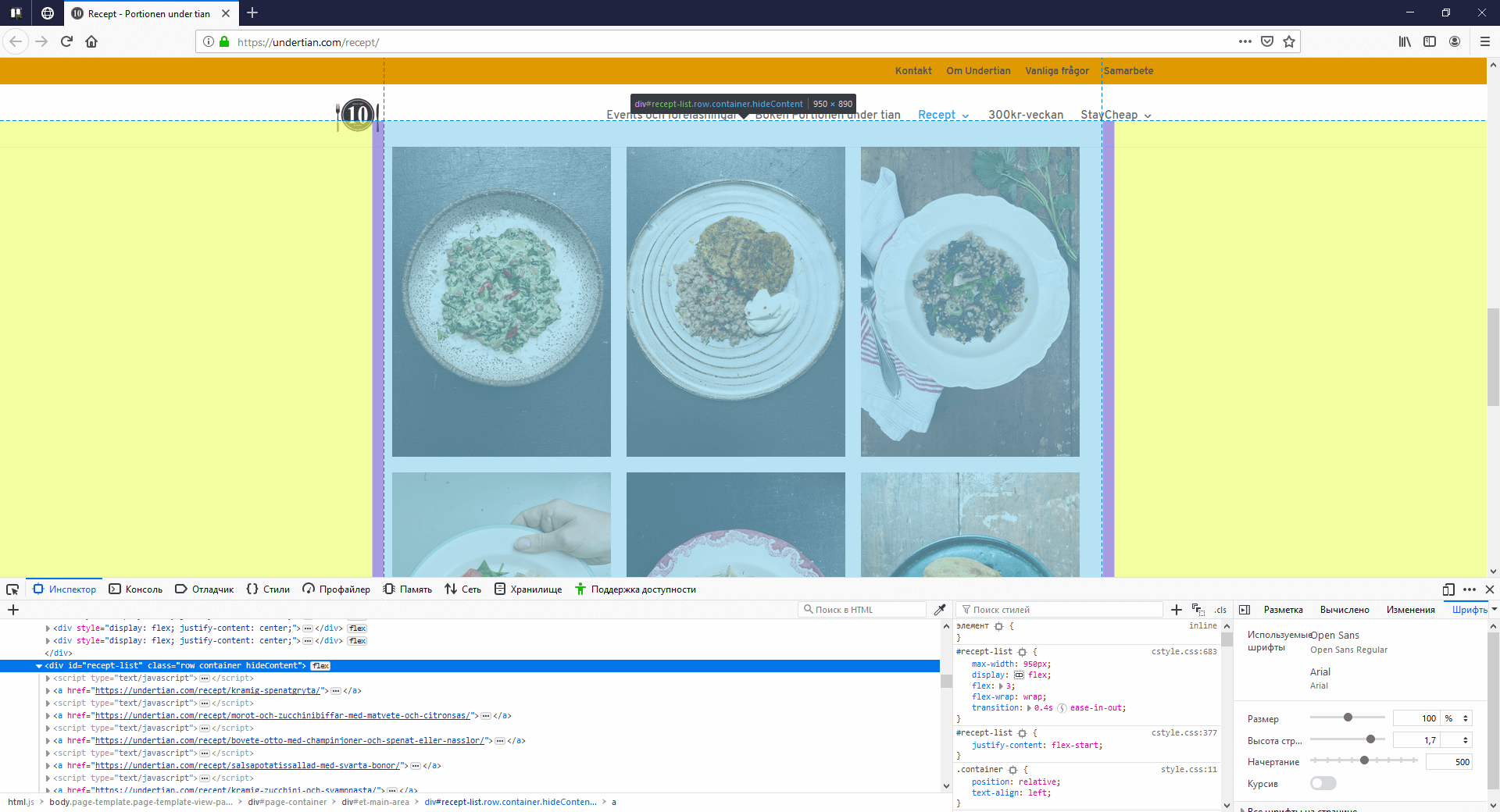
In the picture below, you can see all the recipes in the form of cards. To get detailed information about the recipe, follow the link. All the links are enclosed in the <div> with the CSS class and in tags <a>. Next, you should extract all the links.
var pageUrls = page.Html.CssSelect("div.row a");
The variable pageUrls is a list of type IEnumerable <HtmlNode> where the scraper collects all the links. Also, if you open each <a> tag, you can see a link to the picture and the name of the dish. These parameters will be already extracted at this stage.
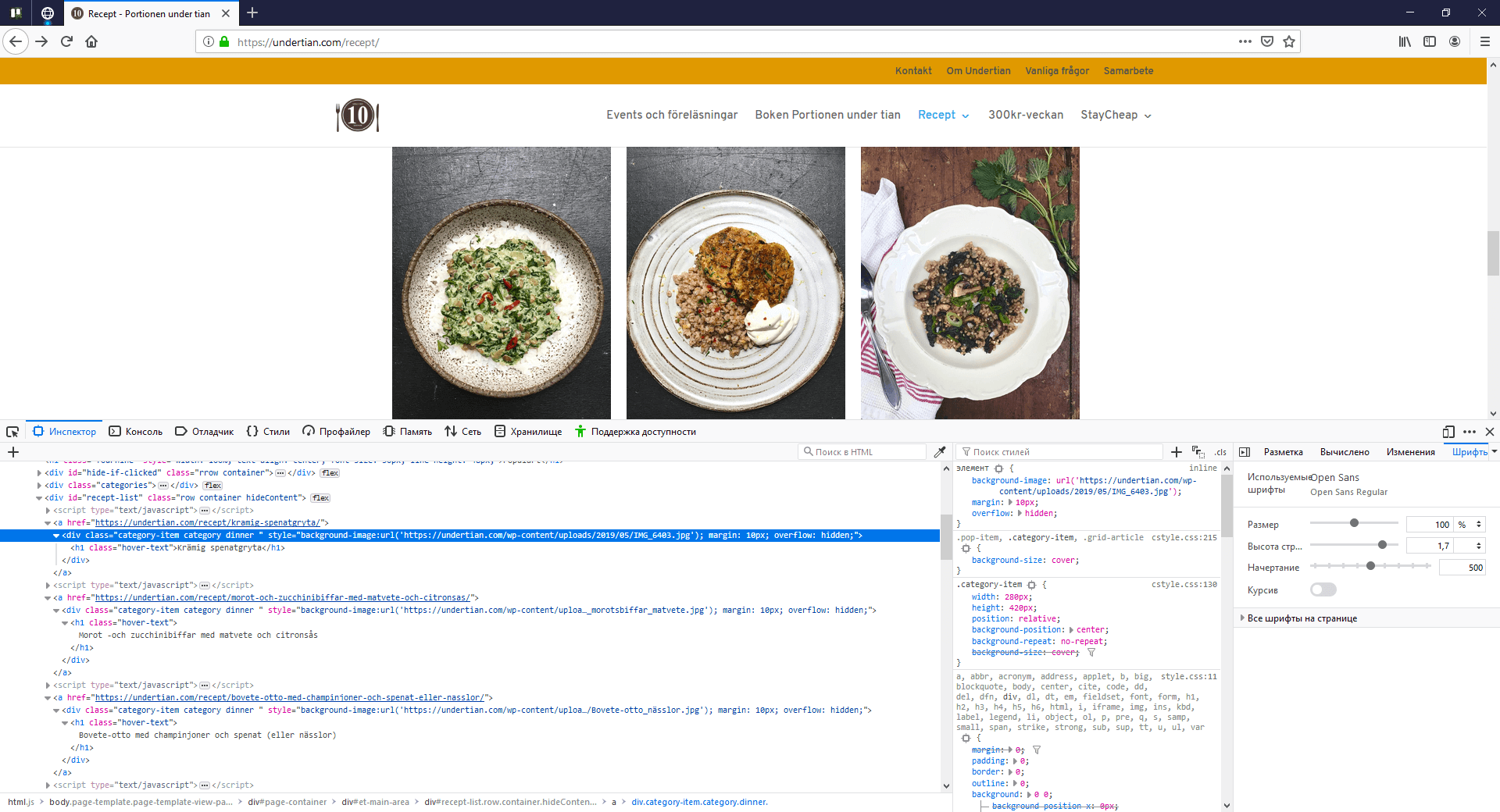
Next, we check for null. If the list is not empty, go through our list.
Selecting one link, scrapper goes on it. We can see it by performing a similar operation manually in a web browser.
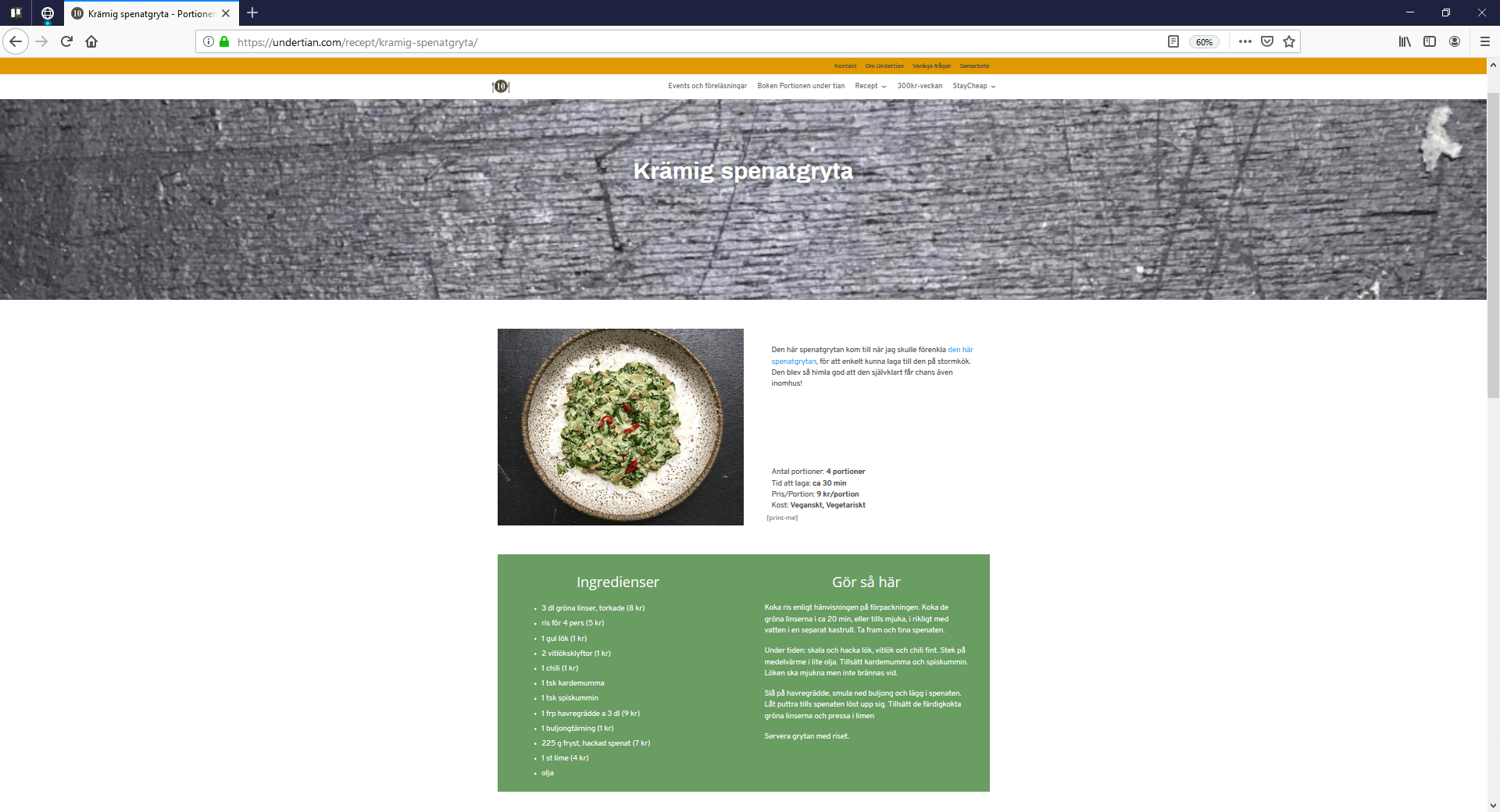
Here you can find all the necessary information about the recipe: a brief description, ingredients, method of preparation, etc. It remains to determine in which tags and in which classes the necessary information is enclosed and specify the settings for the scraper. Using the following instruction, you can define CSS-selector or XPath:
Step 1: Right click on page → Select (Inspect Element)
Step 2: Pick an element from the page
Step 3: Right Click on highlighted HTML → Copy → XPath / CSS-selector
public void Scrapping()
{
Recipe scrapperRecipe = new Recipe();
ScrapingBrowser browser = new ScrapingBrowser();
WebPage page = browser.NavigateToPage(new Uri("https://undertian.com/recept/"));
var pageUrls = page.Html.CssSelect("div.row a");
if (pageUrls != null)
{
foreach (var row in pageUrls)
{
var recipeUrl = row.Attributes["href"]?.Value;
var title = row.InnerText;
scrapperRecipe.Title = title;
WebPage webPage = browser.NavigateToPage(new Uri(recipeUrl));
scrapperRecipe.ExternalLink = recipeUrl;
var discription = webPage.Html.CssSelect( "div.halfie p").FirstOrDefault();
scrapperRecipe.Description = description.InnerText;
var ingredients = webPage.Html.CssSelect("div.content-recept li").FirstOrDefault();
var ingredientsList = new List<string>();
foreach (var ingredient in ingredients)
{
ingredientsList.Add(ingredient.InnerText.Trim() + ",");
}
scrapperRecipe.Ingridients = ingredientsList;
var cookingSteps = webPage.Html.CssSelect("div.content-recept.sp-content p").FirstOrDefault();
scrapperRecipe.CookingSteps = cookingSteps;
var imageUrl = webPage.Html.SelectSingleNode("//*[@id='left-area']/div[1]/div/div/div");
if(imageUrl =! null)
{
var image = (Regex.Match(imageUrl.GetAttributeValue("style", ""), @"(?<=url\()(.*)(?=\))").Groups[1].Value).Replace("'", "");
scrapperRecipe.ImageUrl = image;
}
}
}
return Error();
}
For example, the link was extracted using XPath. In this case, we use the SelectSingleNode method, which takes the XPath parameter. You should put a picture in div with CSS when the issue with extracting a picture occurs.
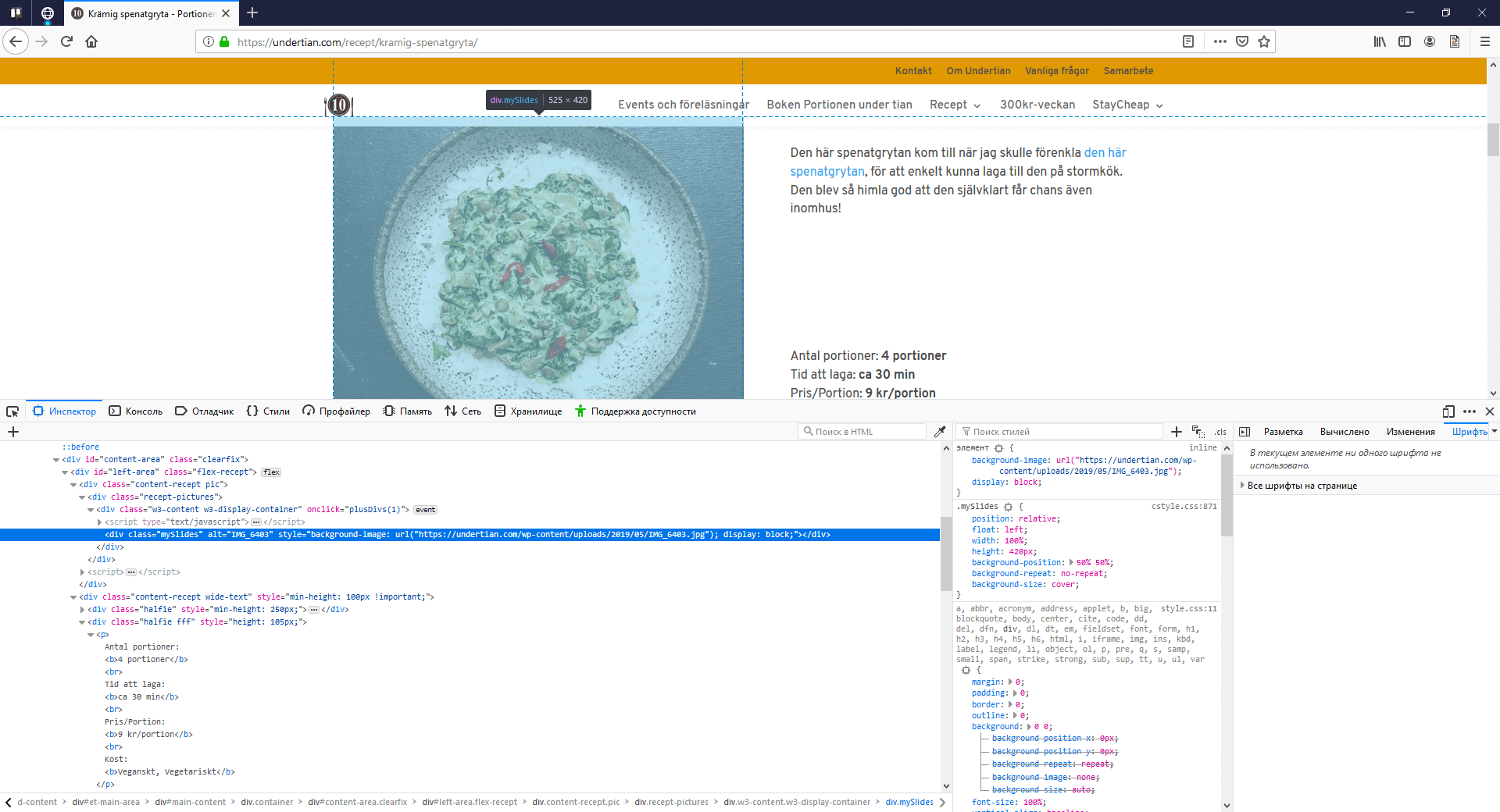
The correct solution in this situation would be to use a regular expression. See CODE.
All data has been collected and can be saved both in a file and in a database.
Conclusion
In this article, you have discovered Web Cleaning with C# and how to create a functional scraper using ScrapySharp library. We have demonstrated one of the options for scraping the page. On the current site, there isn’t any pagination and pop-up elements. But you should understand that the principle is always the same.
We have Scraper and data, what’s next? It’s about filling out forms, modeling user events, such as clicks and other libraries. You can also integrate Scrapers into existing or new projects. No matter what language you used to write Scraper, the main thing is to understand HTML and CSS. As previously mentioned, the Web Scraper will automate collecting, filtering and saving information.

 (10 votes, average: 4.50 out of 5)
(10 votes, average: 4.50 out of 5)Stay tuned. Monthly digest of the best stories.




gabriella_hatchett says:
Hi there, I enjoy reading all of your articles. I wanted to write a little
comment to support you.